こんにちは、コバヤシです。
とある案件で重くなりそうなCSVのバッチ処理があり、稼働中のサーバーに負荷をかけないように、どうにかならないかと試行錯誤してみました。
AWS Transfer Family、Amazon S3とAWS Lambdaを使う方法を試してみたので、今回はその方法を書きたいと思います。
Amazon S3とは
Amazon S3(Simple Storage Service)は、AWSが提供するオブジェクトストレージサービスです。高い可用性と耐久性を持ち、テラバイト単位の大容量データでも効率よく保存できます。
今回の仕組みでは、AWS Transfer Familyを使って転送されたCSVファイルの保存先としてS3を使用し、その後の加工データの保存先にも使用します。
AWS Transfer Family とは?
AWS Transfer Familyは、AWSが提供するサーバーレスのファイル転送サービスです。SFTPやFTPS、FTPといったプロトコルに対応しており、外部システムからAmazon S3に直接ファイルを転送できます。これにより、サーバーを構築する手間を省きながら、安全で効率的なデータ連携が可能になります。
今回はオンプレミスからS3にファイルを転送するのに使用する想定です。
AWS Lambda とは?
AWS Lambdaは、AWSが提供するサーバーレスのコンピューティングサービスです。サーバーを用意せず、イベントが発生するたびに自動でコードを実行できます。必要なリソースだけを使う仕組みなので、コスト効率にも優れています。
今回はAWS Transfer Familyのワークフローを使用してAWS Lambdaでデータ加工を行います。
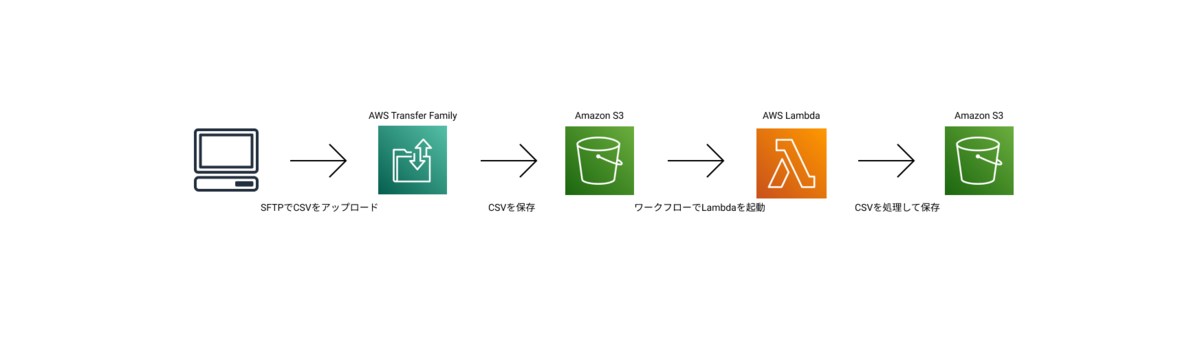
目指す処理の流れ
- CSVファイルのアップロード
CSVファイルがAWS Transfer FamilyのSFTPを介してAmazon S3に保存されます。
SFTPを使うのは、サーバーがAWSを使用していなくても連携できるようにするためです。 - AWS Transfer Familyのワークフロー実行
ファイルがアップロードされると、そのイベントがトリガーとなり、設定されたワークフローが開始されます。このワークフローで、Lambda関数が呼び出されます。 - Lambdaによるデータ加工
LambdaでCSVデータを加工・整形します。
今回は、複数のユーザーのテスト結果を集計する処理を行いたいと思います。 - 加工済みCSVの保存
加工されたCSVデータを別のS3ディレクトリに保存します。これにより、外部システムや他のプロセスが加工済みデータにアクセスできるようになります。
今回はCSVとして保存しますが、直接DBに保存しても良いと思います。
イメージはこのような感じです。
それでは順番に設定を行っていきます。
(1)IAMロールの作成1
まずは、各サービスで使うロールを作成していきます。
Transfer FamilyからS3へアクセスするためのロール
Transfer Familyから使用するS3バケットに対してアクセスできるようにロールを作成し、ポリシーをアタッチします。
- 【信頼されたエンティティタイプ】で【AWSのサービス】を選択し、【ユースケース】で【Transfer】を選びロールを作成します。
- 以下のポリシーを作成し、ロールにアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::xxxxx-bucket", "arn:aws:s3:::xxxxx-bucket/*" ] } ] }
LambdaからS3へアクセスするためのロール
Lambdaから使用するS3バケットに対してアクセスできるようにロールを作成し、ポリシーをアタッチします。
- 【信頼されたエンティティタイプ】で【AWSのサービス】を選択し、【ユースケース】で【Lambda】を選びロールを作成します。
- 以下のポリシーを作成し、ロールにアタッチします。(LambdaがAmazon CloudWatchへログを出力するため、権限を追加しています)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::xxxxx-bucket/*" ] } ] }
(2)Lambda関数の作成
今回はPythonを使用して、各ユーザーの成績の合計を行うこととします。
こんな感じのデータを使用して、各ユーザーの成績を集計を集計させたいと思います。
ユーザー名,教科,点数 ユーザー1,国語,90 ユーザー1,算数,82 ユーザー1,理科,81 ユーザー1,社会,70 ユーザー2,国語,65 ユーザー2,算数,88 ユーザー2,理科,89 ユーザー2,社会,85 ユーザー3,国語,66 ユーザー3,算数,60 ユーザー3,理科,89 ユーザー3,社会,62 ユーザー4,国語,91 ユーザー4,算数,71 ユーザー4,理科,67 ユーザー4,社会,92 ユーザー5,国語,92 ユーザー5,算数,96 ユーザー5,理科,60 ユーザー5,社会,87 ユーザー6,国語,88 ユーザー6,算数,84 ユーザー6,理科,89 ユーザー6,社会,81 ユーザー7,国語,73 ユーザー7,算数,77 ユーザー7,理科,71 ユーザー7,社会,89 ユーザー8,国語,89 ユーザー8,算数,95 ユーザー8,理科,64 ユーザー8,社会,87 ユーザー9,国語,78 ユーザー9,算数,83 ユーザー9,理科,81 ユーザー9,社会,96 ユーザー10,国語,61 ユーザー10,算数,61 ユーザー10,理科,62 ユーザー10,社会,73
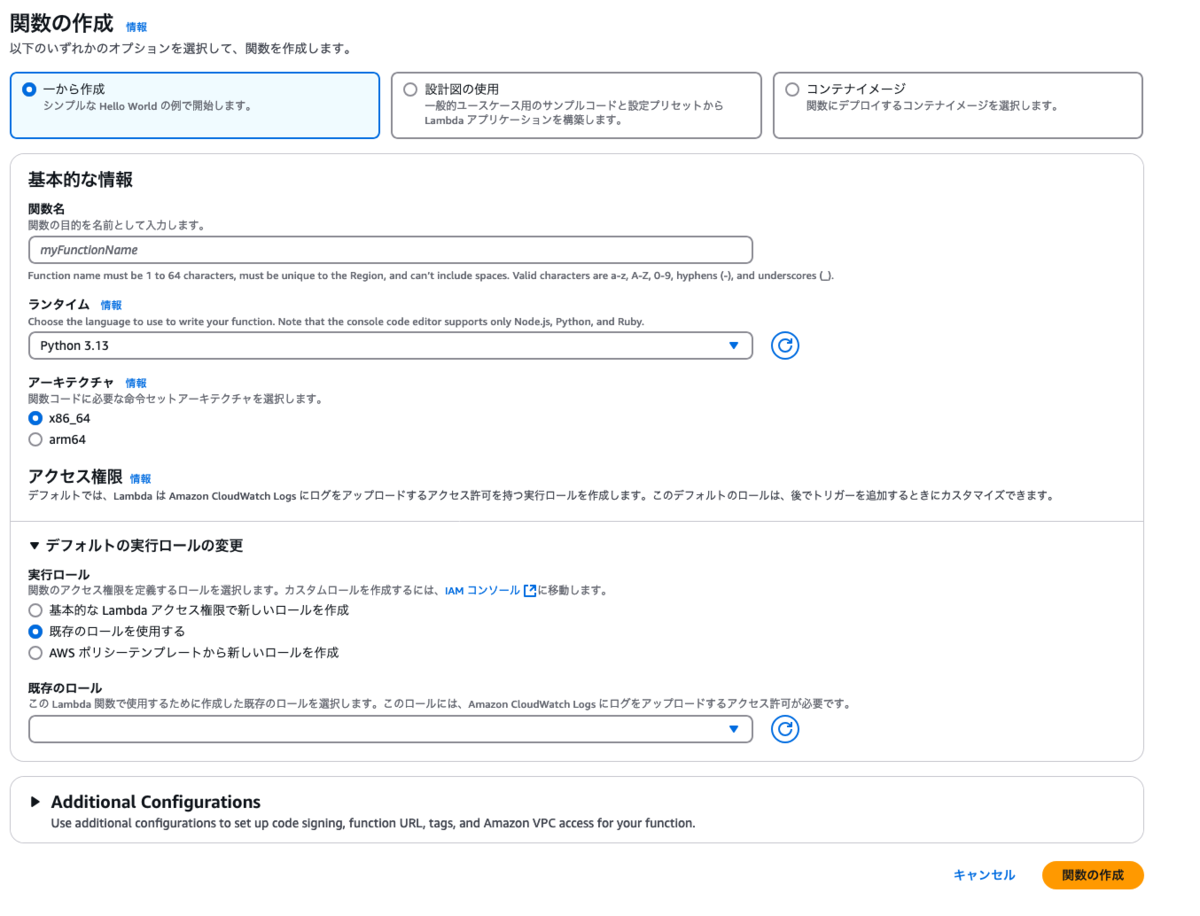
Lambdaの管理画面から関数を作成します。
【実行ロール】では【既存のロールを使用する】を選択し、先に作成した【LambdaからS3へアクセスするためのロール】を指定します。
実際のプログラム部分は、以下のようにします。
import boto3 import csv import io from datetime import datetime, timezone, timedelta # S3クライアントを作成 s3 = boto3.client('s3') def lambda_handler(event, context): # ワークフローのイベントからバケット名とオブジェクトキーを取得 try: bucket_name = event['fileLocation']['bucket'] object_key = event['fileLocation']['key'] except KeyError as e: raise ValueError("入力エラー") # 必要な情報があるか検証 if not bucket_name or not object_key: raise ValueError("入力エラー") try: # S3からCSVファイルを取得 response = s3.get_object(Bucket=bucket_name, Key=object_key) csv_content = response['Body'].read().decode('utf-8') except Exception as e: raise RuntimeError("S3 読み込みエラー") try: # データの処理 reader = csv.DictReader(io.StringIO(csv_content)) user_scores = {} for row in reader: user = row.get('ユーザー名') score = row.get('点数') if not user or not score: continue try: score = int(score) except ValueError: continue if user not in user_scores: user_scores[user] = 0 user_scores[user] += score output = io.StringIO() writer = csv.writer(output) writer.writerow(['ユーザー名', '合計点']) for user, total_score in user_scores.items(): writer.writerow([user, total_score]) # 新しいファイル名を作成 base_name = object_key.split('/')[-1] jst = timezone(timedelta(hours=9)) current_time = datetime.now(jst).strftime("%Y%m%d_%H%M%S") new_file_name = f"{base_name.split('.')[0]}_processed_{current_time}.csv" processed_key = f"{new_file_name}" # S3に保存 output.seek(0) s3.put_object( Bucket=bucket_name, Key=processed_key, Body=output.getvalue(), ContentType='text/csv' ) # 正常終了のレスポンス return { "processedFilePath": processed_key, "message": "処理が成功しました" } except Exception as e: # エラーハンドリング raise RuntimeError("処理に失敗しました")
(3)IAMロールの作成2
Transfer FamilyからLambdaを実行するためのロール
Transfer FamilyからLambda関数を実行できるようにロールを作成し、ポリシーをアタッチします。
- 【信頼されたエンティティタイプ】で【AWSのサービス】を選択し、【ユースケース】で【Transfer】を選びロールを作成します。
- 以下のポリシーを作成し、ロールにアタッチします。Resourceは作成したLambda関数のARNを指定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxx:function:xxxxxx" } ] }
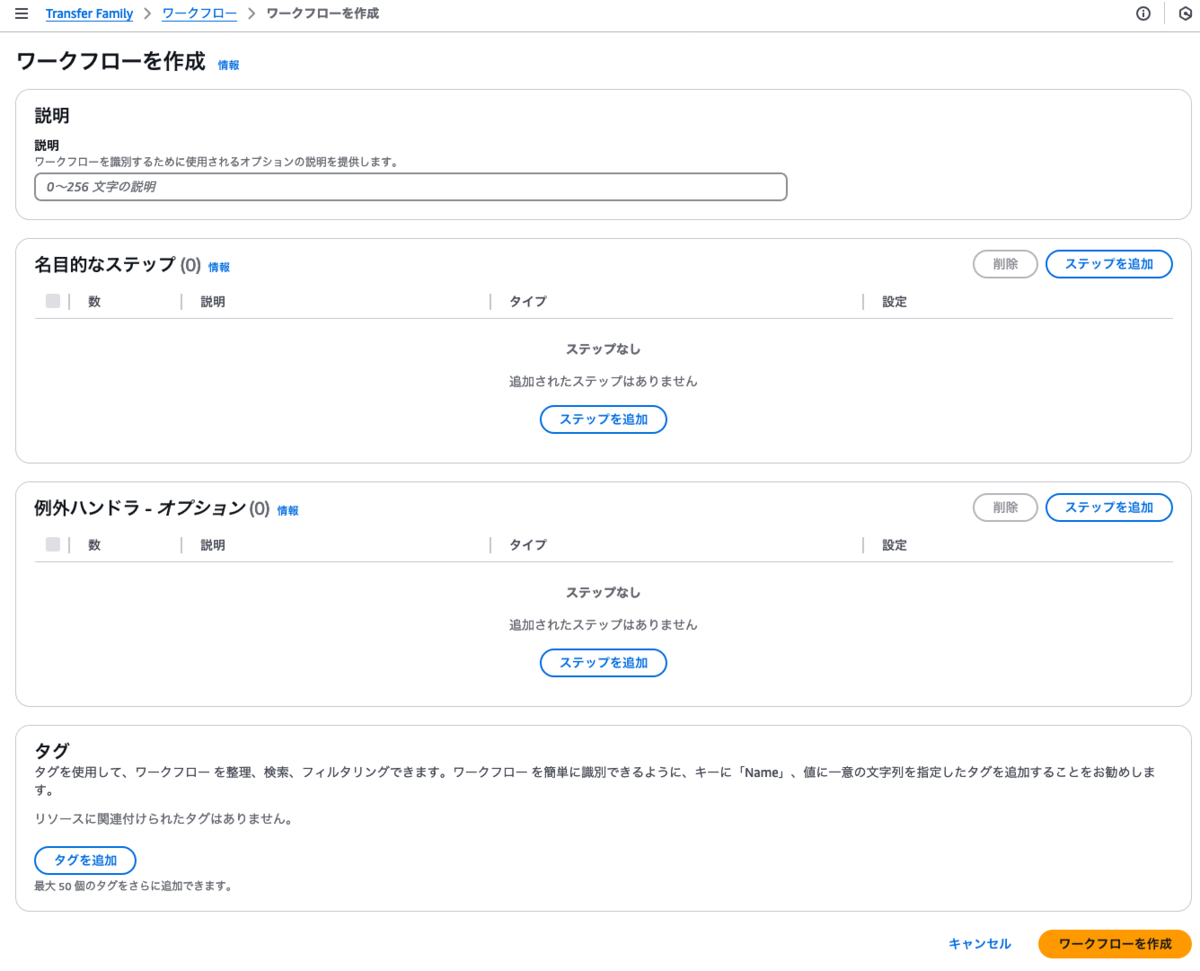
(4)AWS Transfer Familyのワークフローの作成
AWS Transfer Familyで使用するワークフローを先に作成しておきます。
名目的なステップの【ステップを追加】からステップを追加をクリックします。
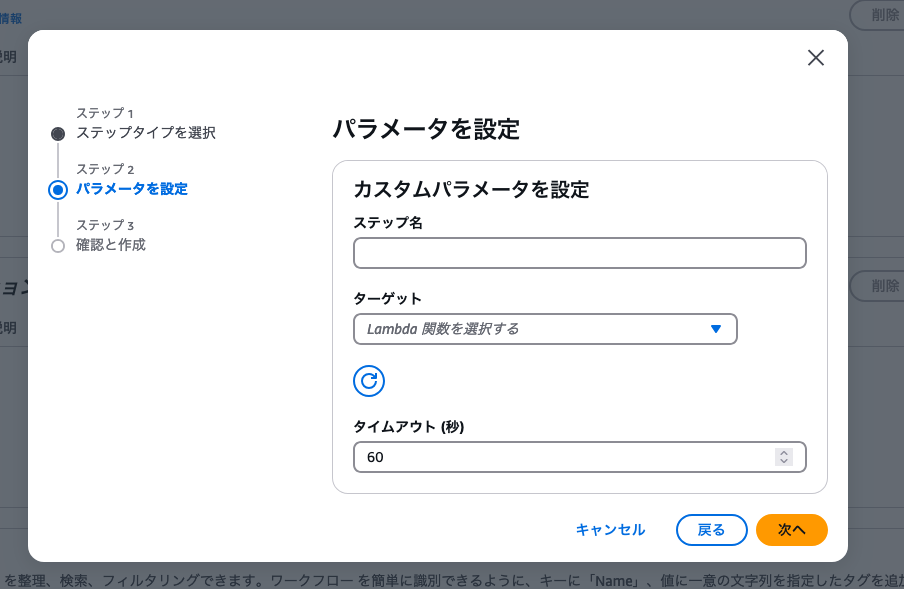
カスタムファイル処理ステップを選択します。
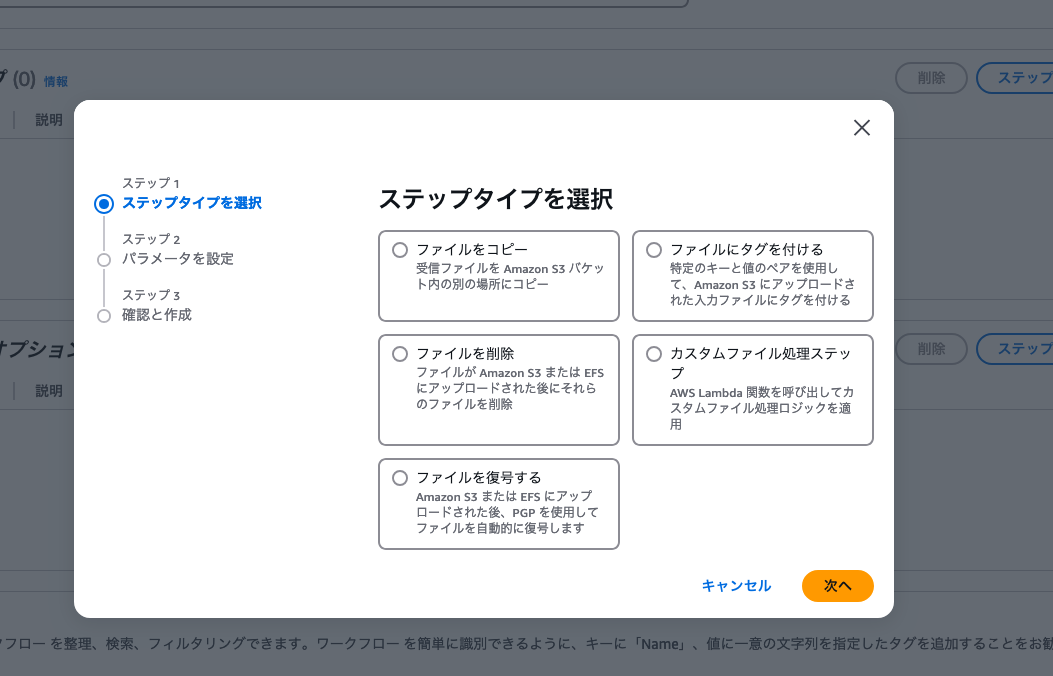
ターゲットに、作成したLambda関数を選択します。
(5)AWS Transfer Familyのサーバー作成
次に、AWS Transfer Familyのサーバーを作成します。
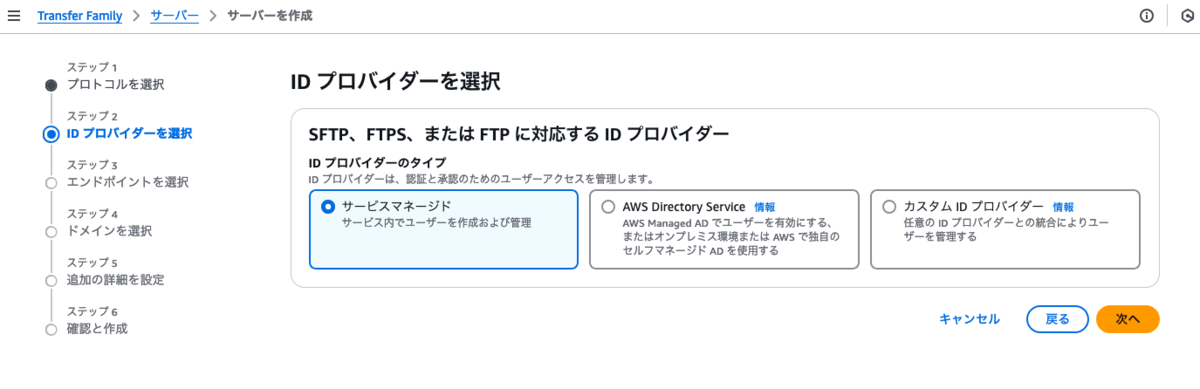
プロトコルはSFTPを選択します。

プロバイダーはサービスマネージドを選択します。
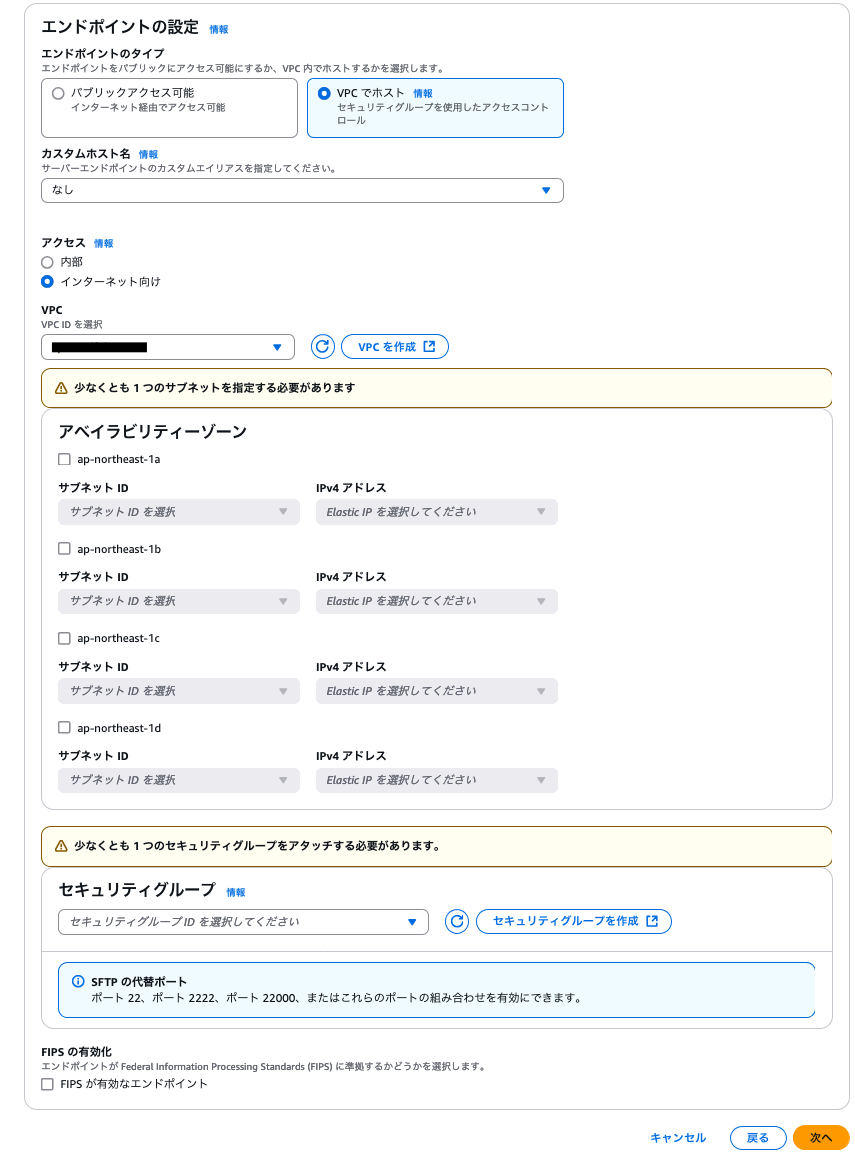
- エンドポイントのタイプは【VPCでホスト】、アクセスは【インターネット向け】を選択します。
- 配置するVPCを選択肢、アベイラビリティゾーンは、SFTPサーバーを配置したい箇所のサブネットを選択してIPを選びます。(空いているElastic IPが無かったら予め取得しておきます)
ドメインはAmazon S3を選択します。
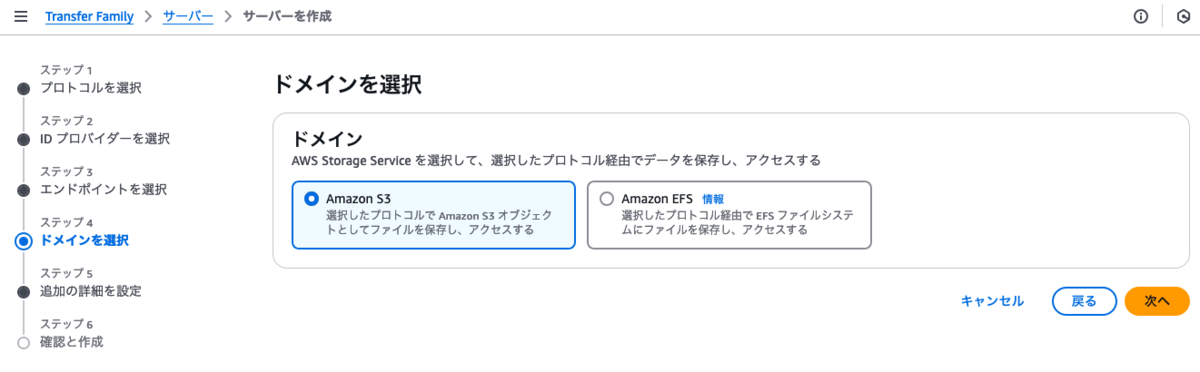
- マネージドワークフローの【完全なファイルアップロードのワークフロー】で先に作成したワークフローを選択します。
- マネージドワークフロー実行ロールで、先に作成した【Transfer FamilyからLambdaを実行するためのロール】を選択します。
- ログ記録ロールはワークフローを選択すると選択出来るようになるので、【AWSTransferLoggingAccess】を選択します。
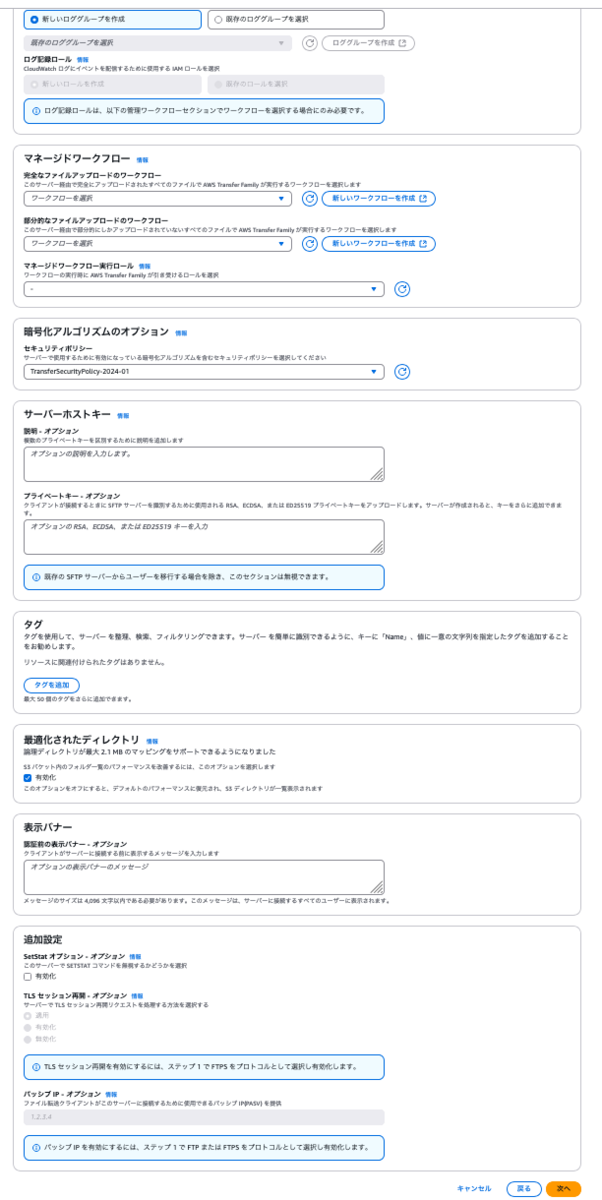
ユーザーの追加
AWS Transfer Familyおサーバーを作成すると、ユーザーなしとなっているのでユーザーを追加します。
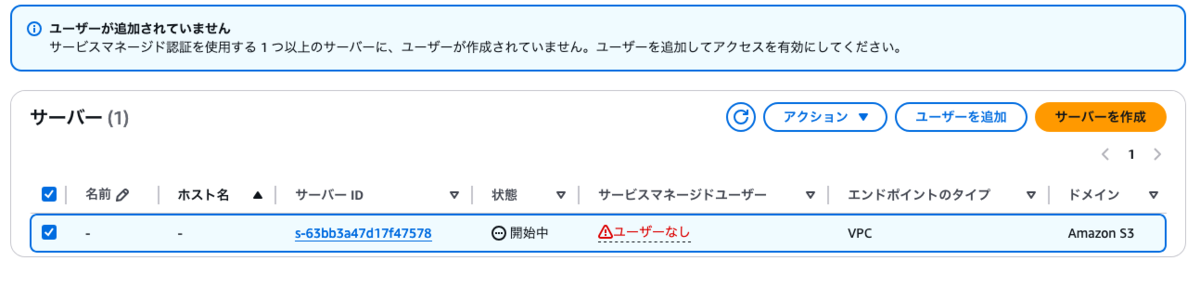
- ロールは、先に作成した【Transfer FamilyからS3へアクセスするためのロール】を選択します。
- ポリシーは【なし】とします。
- ホームディレクトリは、対象のバケットを選択します。
- SSHパブリックキーは、ssh-keygenコマンドで公開鍵と秘密鍵のペアを作成し、公開鍵(.pub)の中身を入力します。
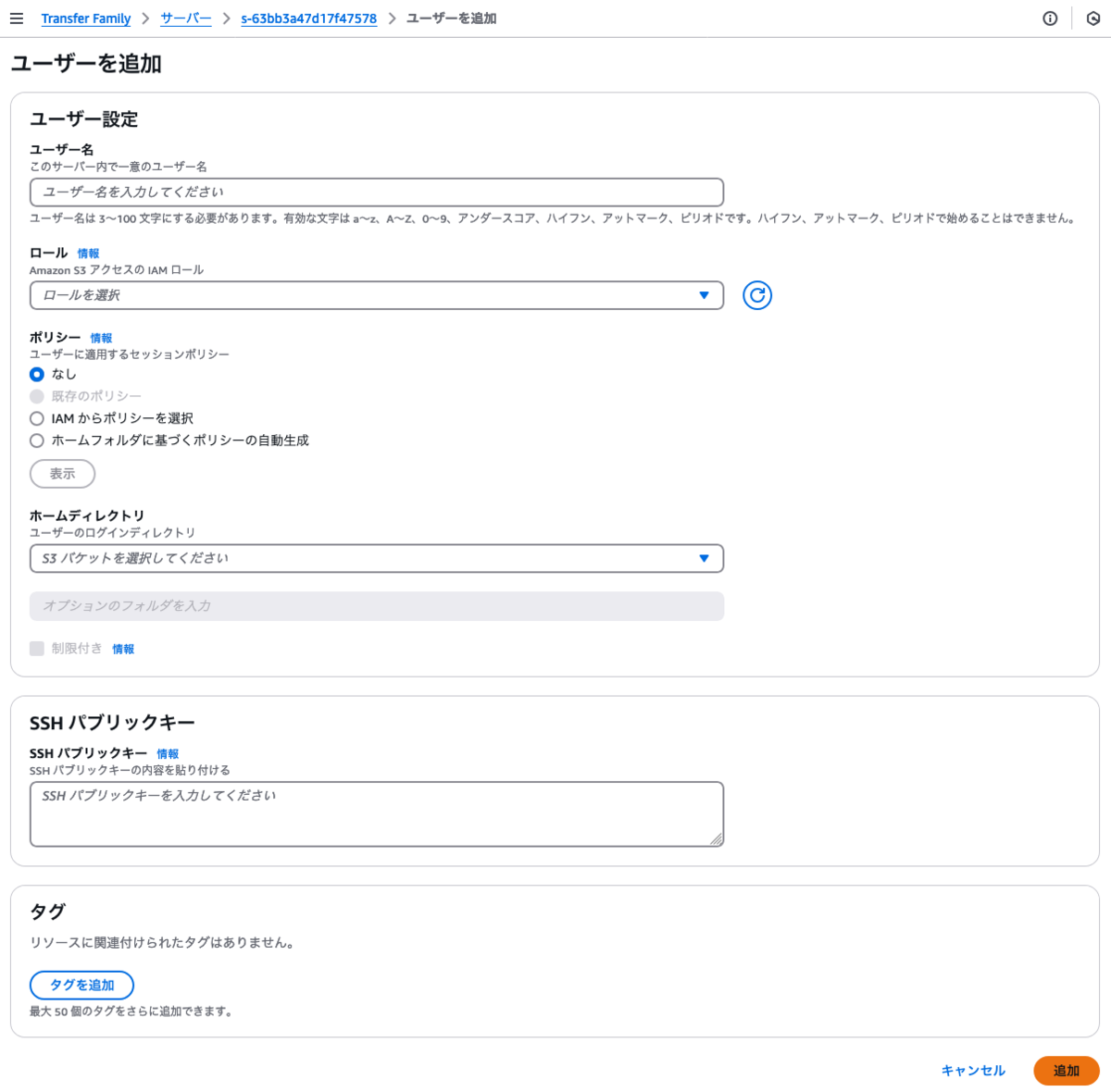
ユーザーが出来たら設定は完了となります。
(6)実行
それでは、CSV(Lambda関数のところに記載したユーザーの成績のCSV)をSFTPでアップします。

すると、処理された結果が、csvとして作成されます。
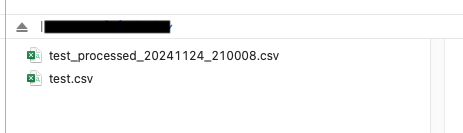
中身は、こんな感じです。
ユーザー名,合計点 ユーザー1,323 ユーザー2,327 ユーザー3,277 ユーザー4,321 ユーザー5,335 ユーザー6,342 ユーザー7,310 ユーザー8,335 ユーザー9,338 ユーザー10,257
無事、処理されたようです。
デメリット
ここまで頑張ってAWS Transfer FamilyとLambdaを組み合わせた構成を作成してきましたが、いくつか注意点があります。
費用が高い
AWS Transfer Familyは、利用時間とデータ転送量に応じて課金されます。例えば、1日あたり100MBのファイルを転送し、月30日間稼働した場合の費用を試算すると以下のようになります。
- SFTPサーバー稼働時間:1時間あたり0.30 USD × 720時間(30日間) = 216.00 USD
- データ転送量:1GBあたり0.04 USD × 3GB(30日間) = 0.12 USD
合計で約216.12 USD(約3万円)/月がかかります。
停止することは可能ですが、課金は止まらないため、「必要なときだけ起動」という運用はできないようです。
バッチ処理だけでこれだけ費用を掛けるかというと、厳しい感じですね。
エラー時の対応が難しい
AWS Transfer Familyのワークフローはシンプルですが、エラー発生時の通知や再処理の仕組みを自分で追加する必要があり、逆にこちらの対応で手間が掛かりそうです。失敗時の例外ハンドラも設定できますが、処理の再実行やエラー通知を柔軟に管理するには、AWS Transfer Family単体では限界がありそうです。
まとめ
AWS Transfer Familyは簡単に構築できるため、初期段階では非常に便利です。ただし、費用が高いことやエラー処理の難しさを考えると、運用を続けるには厳しいと感じました。
EC2を使っているのならば、AWS Transfer Familyを使わずに直接マウントする方法が良いと思うし、EC2を使って無くてもAWS SDKを使う方法もあります。さらにはEventBridgeやSQSを使った構成にすることで、コストを抑えつつ、エラー対応が柔軟に出来そうです。
次回は、この方法を試してみたいと思います。
お知らせ
2024/12/13(金)19:00〜「静岡ITもくもく会」を開催します。興味のある方は是非ご参加ください。
お申し込みは下記connpassからお願いします。